流水线组件的选择:任务简单性
除了数据可用性之外,你还应该考虑流水线组件选择的第二个因素:独立的组件使得任务简单了多少?你应该尽可能地选择那些易于构建或学习的独立流水线组件,但对一个组件而言, “易于” 学习指的是什么呢?
考虑下面列出的机器学习任务,它们的难度逐级递增:

- 分类判断某张图片是否过度曝光(就像上面这张图片);
- 分类判断某张图片拍摄于室内还是室外;
- 分类判断某张图片中是否有猫;
- 分类判断某张图片中是否有黑白两色皮毛的猫;
- 分类判断某张图片中是否有暹罗猫(一种特殊的猫)
这些图像分类任务都属于二分类任务——你需要输入一张图片,输出 0 或者 1. 但列出的前面几个任务看起来 “更易于” 使神经网络进行学习。你将能够通过较少的训练样本来学习更加简单的任务。
对于使问题变得简单或困难的原因,机器学习领域尚未给出一个较好的正式定义。随着深度学习和多层神经网络的兴起,我们有时认为,如果一个任务可以用更少的计算步骤(对应于一个浅的神经网络)来实现,那么相对于需要更多的计算步骤(对应于一个深的神经网络),这个任务就 “更简单” 了。但这些都是非正式的定义。
在信息论中有 “Kolmogorov 复杂度” 的概念,一个学习函数的复杂度是产生该函数的计算机程序的最短长度。然而这一理论概念在人工智能领域几乎没有什么实际的应用。参考:https://en.wikipedia.org/wiki/Kolmogorov_complexity
如果你能够完成一个复杂的任务,并将其分解为更简单的子任务,然后显式编写子任务步骤代码,那么你就会给算法一些先验知识,从而帮助它更有效地学习任务。

假设你正在构建一个暹罗猫检测器。下面是一个纯粹的端到端架构:

与此相反,你可以分成两个步骤来形成流水线:

第一步:(猫检测器)检测图像中所有的猫。
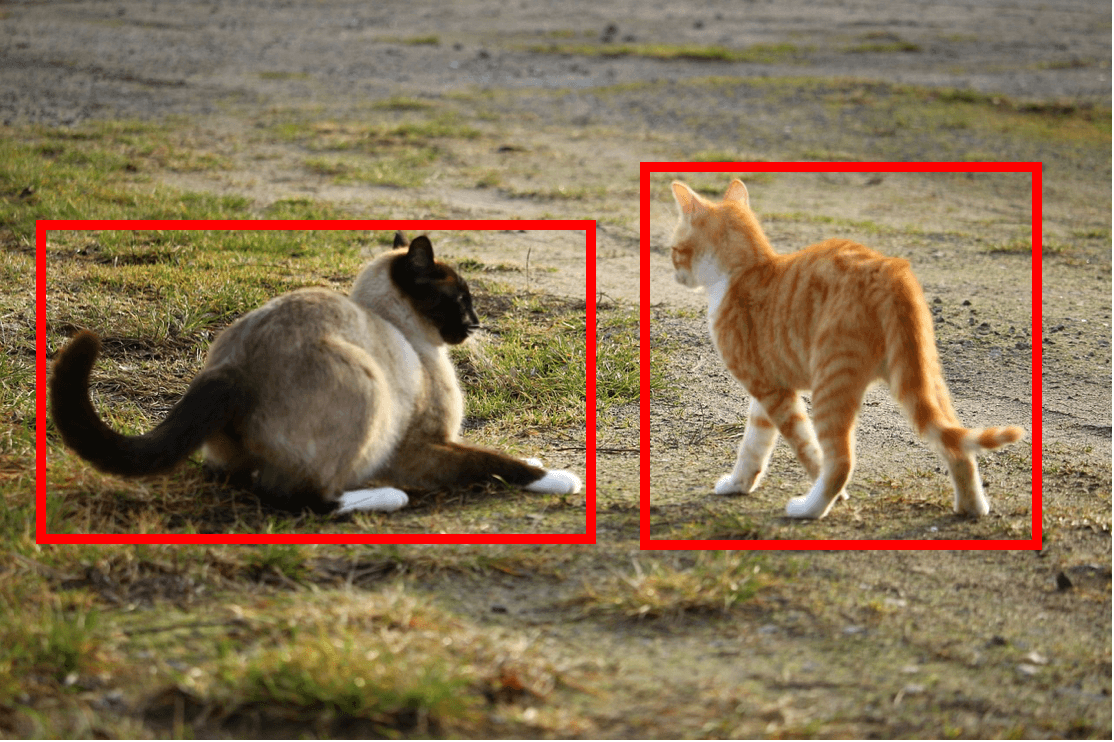
第二步:将每一块被检测到的猫的图像传送给猫种类分类器(每次一张),如果其中任何一只猫是暹罗猫,则在最后输出 1.
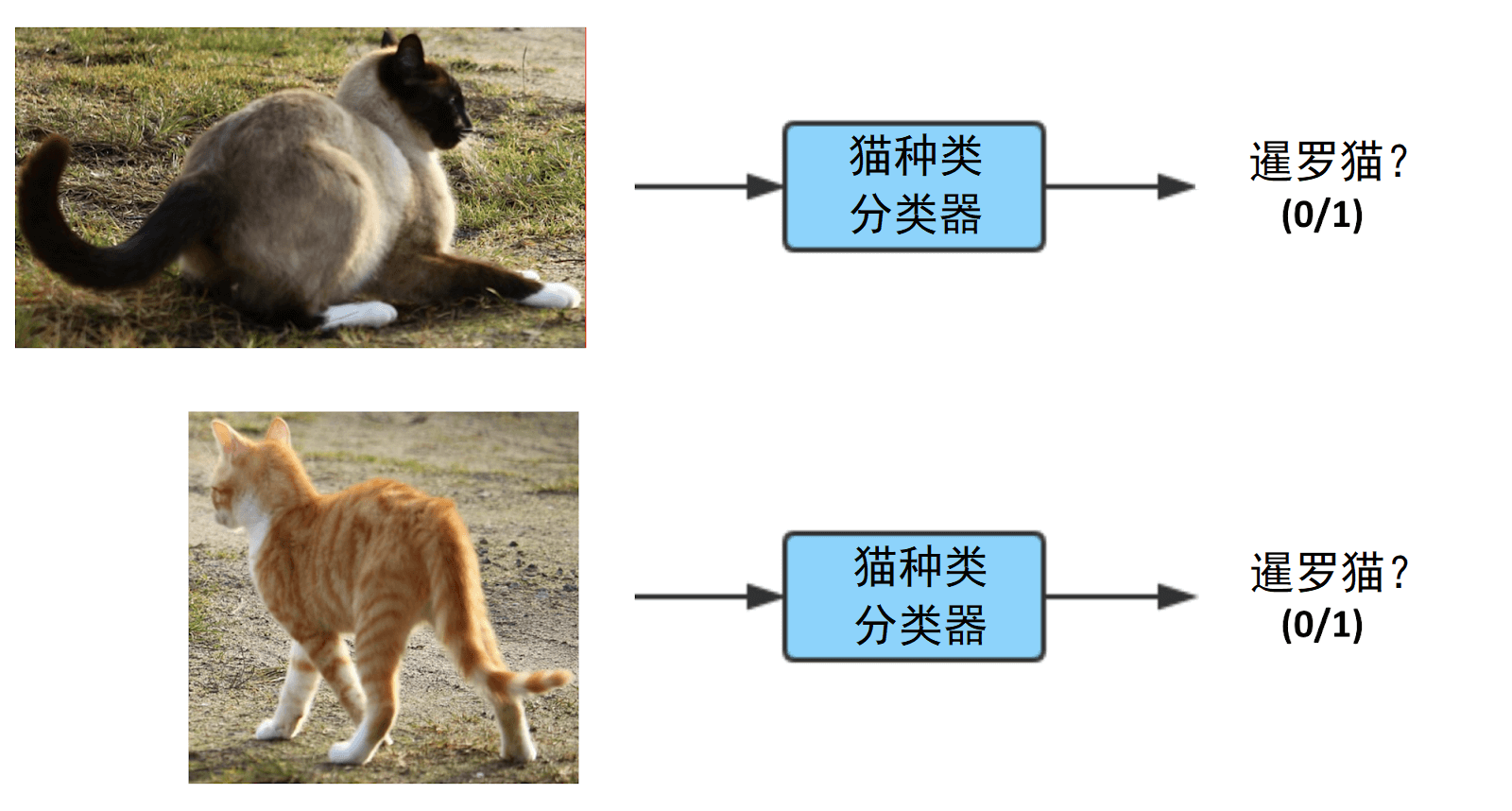
与仅仅使用标签 0/1 来训练一个纯粹的端到端分类器相比,流水线中的两个组件——猫咪检测器和猫种类分类器——似乎更容易进行学习,而且需要更少的数据。
如果你熟悉实际运用中的对象检测算法,你将认识到它们并不是只学习 0/1 图像标签,而是作为训练数据的一部分取代边界框进行训练,对它们的讨论超出了本章的范围。如果你想了解更多关于这种算法的知识,请参阅 Coursera 的 Deep Learning 专项课程(http://deeplearning.ai)。
最后一个例子,让我们回顾一下自动驾驶流水线。
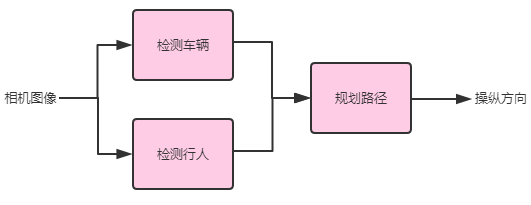
通过使用该流水线架构,你可以告诉算法总共有三个关键的步骤:(1)检测其他车辆,(2)检测行人,(3)为你的车规划一条道路。此外,每一个步骤都是相对简单的功能——因此可以用更少的数据来学习——而不是纯粹的端到端方法。
总而言之,当决定流水线组件的内容组成时,试着构建这样的流水线,其中每个组件都是一个相对 “简单” 的功能,因此只需要从少量的数据中学习。