解读学习曲线:高偏差
假设你的开发误差曲线如下图所示:
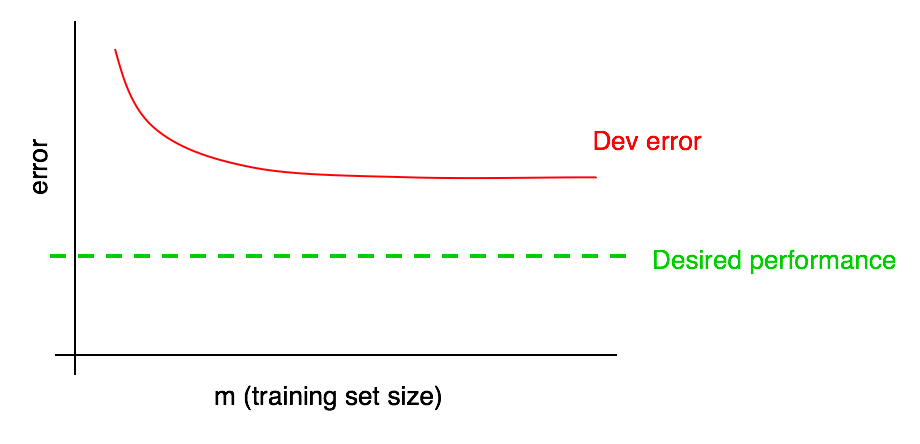
我们之前提到,如果开发误差曲线趋于平稳,则不太可能通过添加数据来达到预期的性能,但也很难确切地知道红色的开发错误曲线将趋于何值。如果开发集很小,或许会更加不确定,因为曲线中可能含有一些噪音干扰。
假设我们把训练误差曲线加到上图中,可以得到如下结果:
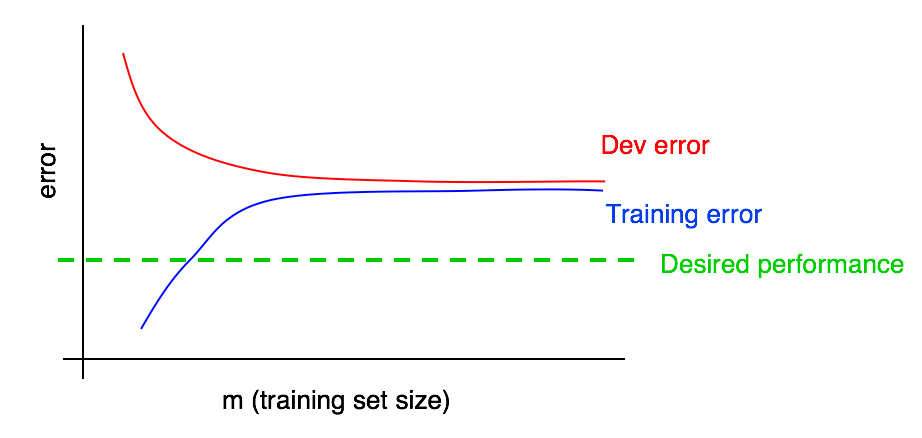
现在可以绝对肯定地说,添加更多的数据并不奏效。为什么呢?记住我们的两个观察结果:
- 随着我们添加更多的训练数据,训练误差变得更糟。因此蓝色的训练误差曲线只会保持不动或上升,这表明它正远离期望的性能水平(绿色的线)。
- 红色的开发误差曲线通常要高于蓝色的训练误差曲线。因此只要训练误差高于期望性能,通过添加更多数据来让红色开发误差曲线下降到期望性能水平之下也基本没有可能。
在同一张图中检查开发误差曲线和训练误差曲线可以让我们对推测开发误差曲线的走势更有信心。
为了便于讨论,假设期望性能是我们对最优错误率的估计。那么上面的图片就是一个标准的“教科书”式的例子(具有高可避免偏差的学习曲线是什么样的):在训练集大小的最大处(大致对应使用我们所有的训练数据),训练误差和期望性能之间有较大的间隙,这代表可避免偏差较大。此外,如果训练曲线和开发曲线之间的间隙小,则表明方差小。
之前,我们只在曲线最右端的点去衡量训练集误差和开发集误差,这与使用所有的可训练数据训练算法相对应。绘制完整的学习曲线将为我们呈现更全面的结果图片,显示算法在不同训练集大小上的表现。