端到端学习的更多例子
假设你正在构建一个语音识别系统,你的系统可能需要三个组件:

它们的工作形式如下:
- 计算特征(compute features):提取人工设计的特征,如 MFCC (Mel-frequency cepstrum coefficients,频谱系数)特征,以此来试图捕捉对话的内容,而忽略不太相关的属性,比如说话者的音高。
- 音素识别器(phoneme recognizer):一些语言学家人为,有一些基本的声音单元叫做 “音素” 。 例如, “keep” 中的 “k” 和 “cake” 中的 “c” 是相同的音素,而这个系统试图识别音频片段中的音素。
- 最终识别器(final recognizer):以已识别音素的序列为序,并试着将它们串在一起,形成转录输出。
与此相反,端到端系统可能会输入一个音频片段,并尝试直接输出文字记录:

到目前为止,我们只描述了纯线性的机器学习 “流水线”:输出顺序地从一个阶段传递到下一个阶段。实际上流水线可能会更复杂。例如,这是一个自动驾驶汽车的简单流水线架构:
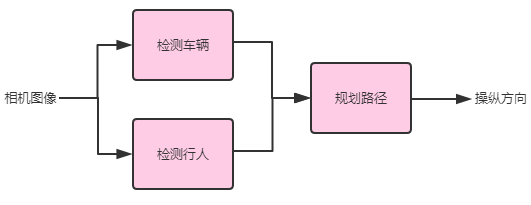
它拥有三个组件:一个使用相机图片检测车辆,一个检测行人,最后一个组件则为我们自己的车规划路径,从而避让车辆和行人。
并不是流水线中的每一个组件都需要进行学习。例如在文献 “robot motion planning” 中对汽车的最终路径规划提出了许多算法,而其中的一些算法并不涉及到学习。
相反,端到端的方法可能会尝试从传感器获取输入并直接输出转向方向:

尽管端到端学习已经在许多领域取得了成功,但它并不总是最佳方案。端到端的语音识别功能很不错,但我对自动驾驶的端到端学习持怀疑态度。在接下来的几章将会解释原因。