流水线组件的选择:数据可用性
在构建非端到端的流水线系统时,什么样的流水线组件可作为合适的选项呢?对流水线的设计将极大地影响整个系统的性能,其中一个重要因素是,是否能够轻松地收集到数据来训练每个组件。
例如,考虑下面这个自动驾驶架构:
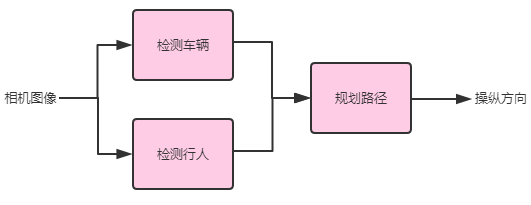
你可以使用机器学习算法进行车辆和行人的检测,另外要获取这些数据也并非难事——如今有许多含有大量带车辆和行人标记的计算机视觉数据集。你也可以通过众包市场(比如 Amazon Mechanical Turk)获得甚至更大规模的数据集。因此,获取训练数据来构建车辆检测器与行人检测器相对而言是比较容易的。
相反,考虑一种纯端到端的方式:

为了训练这样一个系统,我们需要一个包含 <图像,操纵方向> 数据对的大型数据集。然而让人们在驾驶汽车时收集汽车的操纵方向的数据是非常费时费力的,你需要一辆特殊配置的汽车,且需要巨大的驾驶量来涵盖各种可能的场景。这就使得端到端系统难以进行训练,获得大量带标记的行人或者是汽车图像反而要容易得多。
更常见的情况是,如果有大量的数据可以被用来训练流水线的 “中间模块” (例如汽车检测器或行人检测器),你便可以考虑使用多段的流水线架构。因为可以使用所有可用数据进行训练,所以这种结构可能是更优的。
在更多端到端数据变得可用之前,我相信非端到端的方法对于自动驾驶而言是更有希望的——它的体系架构更匹配于数据的可用性。